Les pièges des graphes moyennés à 5 minutes
Si votre enfant s’impatiente, a du mal à finir les 5 minutes de marche jusqu’à la maison, vous pouvez lui demander de compter 5 fois jusqu’à 60 et bien souvent, le temps de cette diversion, la balade est finie et il n’a pas trouvé cela si long ! C’est magique l’enfance.
Bien, maintenant, si votre utilisateur SAP s’impatiente pour entrer sa commande dans l’ERP. Essayez donc de lui demander d’attendre 5 minutes pour lui prouver, graphique à l’appui qu’il n’y a pas de problème de performance !
Voilà, en substance pourquoi les moyennes à 5 minutes ne vous parlent PAS de performance.
Les utilisateurs d’application ne sont pas aussi facile à feinter que votre enfant de 6 ans. Ils ne font pas de « moyenne à 5 minutes » dans leur tête, si ça rame 40 secondes toutes les 5 minutes, c’est insupportable dans son travail… et invisible dans un graphique moyenné à 5 minutes.
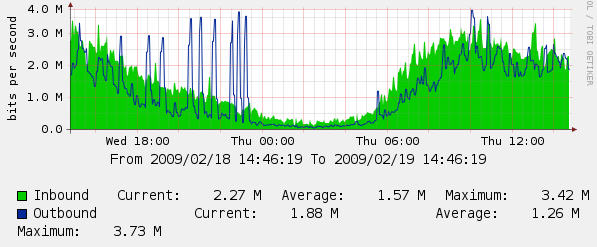
Si vous utilisez des outils de mesure qui échantillonnent à 5 minutes ou plus : des requêtes SNMP vers vos routeurs, switchs, serveurs, etc représentées graphiquement avec MRTG, PRTG, RRDtools, Cacti, ou tout autre outil de Network ou IT Management, qu’il s’agissent de charge réseau en kbit/s, de latence en ms ou bien d’autres métriques des couches basses ; alors dites-vous que la plupart du temps vous ne savez pas ce que vit l’utilisateur.
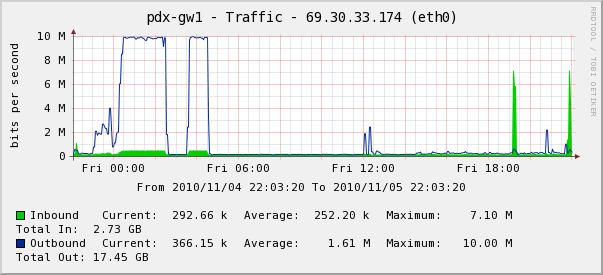
Evidemment, si vous voyez un pic énorme (charge à 100%, latence qui s’envole…), voire un plateau de saturation, avec une granularité à 5 minutes, vous pouvez en déduire que l’utilisateur à du drôlement souffrir pendant 5 minutes ! Mais l’inverse n’est pas vrai : l’utilisateur peut VRAIMENT souffrir, même pendant 5 minutes voire tout le temps, sans que vous n’y voyiez rien sur vos graphes ! Il ne faut pas confondre saturation persistente et congestion transitoire, vous voyez le premier, pas forcément le second.
Pourquoi ? Parce que ! 100 et 0 font une moyenne de 50… qui se souviendra du 100 ? Il suffit de dizaines de secondes d’attente à 100% sur 5 minutes, d’une charge moyenne à 60% sur 5 minutes mais en dents de scie à une échelle de temps inférieure qui vous soit inaccessible (qui a dit Citrix ?), il suffit aussi que ce ne soit pas qu’une histoire de bande passante… il suffit de peu en fait.
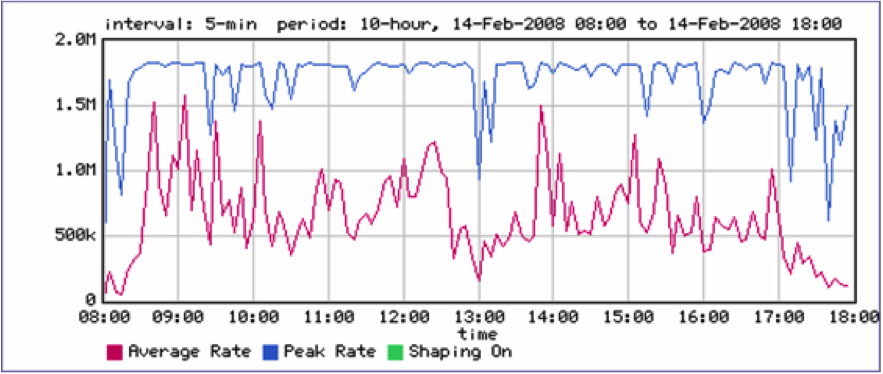
Comment ça « faut voir » ? Très bien, voyons ça. Le graphe ci-dessous, utilisant un équipement en lecture directe et non un polling SNMP, vous donne la charge d’un lien à 1,8 Mbit/s moyennée à 5 minutes en rouge (tout a fait raisonnable, non ?) et en bleu la seconde la plus chargée dans chaque intervalle… surprise, on est au taquet à un moment donné dans chacune des tranches de 5 min. Alors, elle n’est pas visible la congestion maintenant ?
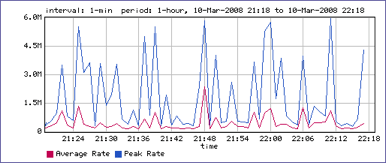
Et ci-dessous, un autre graphe de charge moyenné à 1 minute en rouge (vous avez multiplié par 5 la précision !) et idem en bleu la seconde la plus chargée dans chaque minute. Finalement, il y a peut-être des perturbations possibles par instants.
Aussi, je vous encourage à prendre ces outils de graphes à 5 minutes pour ce qu’ils sont : des outils « moyens », de monitoring général, de détection de catastrophe (trop tard d’ailleurs !), de capacity planning (à postériori !)… mais pas de mesure de performance vue de l’utilisateur.
Merci de m’avoir lu jusque là. Ca fait du bien d’en parler ![]()
P.S. Si vous n’avez que des graphes de charge à 5 minutes pour évaluer la performance des applications pour vos utilisateurs… il faut peut-être faire quelque chose ! Des solutions existent, alors si les symptômes persistent, consultez !